
Для обеспечения верного алгоритма индексации торговых онлайн-площадок в поисковиках применяется такой инструмент, как robots.txt.
Большинство вебмастеров из-за простоты использования этого инструмента используют лишь его, что приводит к появлению в поисковой выдаче "шлака".
В таких обстоятельствах важно понять, что это за файл и какие ошибки необходимо избегать для правильной настройки поисковой выдачи.
Для чего используется Robots.txt?
Файл robots.txt является исключением для поисковых роботов. Он размещен в корневой директории сайта. В этом документе прописываются ограничения для роботов относительно доступа к отдельным элементам сайта. Использование этого документа является полностью добровольным.
Путем использования robots.txt собственники веб-ресурсов показывают роботам поисковиков, перечень страниц, которые не следует индексировать.
В начале процесса изучения сайта поисковой робот загружает robots.txt. Если не используются какие-то иные методы ограничения индексации, кроме robots.txt при отсутствии такого файла поисковой робот начнет индексировать все страницы сайта. В итоге это может привести к следующим негативным последствиям:
• Длительность пребывания робота на сайте ограничена, поэтому он может попросту не успеть добраться до основного контента ресурса;
• Под индексацию может попасть много лишней информации, которая не представляет пользователям никакого интереса, что приведет к ухудшению позиций сайта в итоговой поисковой выдаче;
• В общий доступ могут попасть личные данные юзеров сайта.
За счет использования директив, происходит процесс передачи инструкций поисковикам. С помощью всего лишь двух строчек, указанных в файле robots.txt можно полностью оградить ресурс от поисковой индексации:
User-agent: *
Disallow: /
Символ * в строчке User-agent: указывает на то, что такая директива будет распространена на всех поисковых роботов. Кроме того, можно сделать так, чтоб директива распространялась, лишь на конкретного робота. Для этого нужно вместо символа * поставить название робота.
Процесс выполнения директив полностью подчинен некоторым правилам, а именно:
• Вся информация, которая не ограждена директивой Disallow, отличается полной открытостью для индексации;
• Размещение директив и их порядок никак не отражается на их исполнении;
• Сперва будут выполняться те директивы, которые вмещают в себя меньше символов в URL-префиксе;
• Если директивы обладают аналогичной численностью символов в структуре префикса, сначала будут выполняться директивы Allow.
Все требования и синтаксис файла robots.txt можно найти на веб-ресурсе robotstxt.org. Одновременно с этим, во всех поисковиках применяются собственные директивы. Так, к примеру, для Яндекса нужно прописать директиву с обозначением главного зеркала веб-ресурса:
Host: https://www.yoursite.com
или
Host:https://yoursite.com
Все нюансы формирования robots.txt для конкретных поисковых роботов можно найти в справке Яндекса, Google и иных поисковых систем.
Robots.txt для онлайн-магазина
Если речь идет об обычных информационных ресурсах, то зачастую никаких проблем с использованием robots.txt не возникает. Чаще всего просто этот файл скачивается с CMS, после чего он немного корректируется исходя из специфики конкретного сайта, и все будет отлично работать.
Но ситуация, когда речь идет об интернет-магазинах немного отличается:
• Тут структура имеет более разветвленное строение;
• Интернет-магазины часто обладают собственными региональными поддоменами, для которых следует создавать отдельный файл robots.txt;
• Структура торговых онлайн-площадок отличается более динамичным строением. Внутри таких сайтов постоянно происходят всевозможные изменения, которые важно своевременно учитывать при индексации ресурса;
• Каждый интернет-магазин должен с особой скрупулезностью подходить к вопросу защиты персональных данных так, как при их утечке репутация ресурса может сильно пострадать, что повлечет за собой крупные финансовые издержки.
В действительности, особого значения нет, для какого именно сайта будет составляться файл robots.txt. Все правила и директивы работают одинаково в отношении любого сайта. Но из-за особой специфики интернет-магазинов, подход к созданию файла robots.txt должен быть более внимательным.
Что нужно оградить от индексации?
От индексации во всех случаях следует оградить панель администратора, а также системные файлы сайта. Также панель администратора и файлы, где хранится информация о пользователях, нужно дополнительно защитить отдельным паролем.
Во всех CMS есть своя собственная структура файловой системы, по этой причине директивы robots.txt, которые должны закрыть служебные данные будут иметь некоторые отличия. Пример директив, которые помогают закрыть служебные файлы:
WordPress:
User-agent: *
Disallow: /wp-admin # панель администратора
Disallow: /wp-includes # данные движка
Disallow: /wp-content/plugins # инсталлированные дополнения
Disallow: /wp-content/cache # данные, которые были кешированы
Disallow: /wp-content/themes # темы
Opencart:
User-agent: *
Disallow: /admin # панель администратора
Disallow: /catalog # файлы витринного интерфейса
Disallow: /system # файлы системы
Disallow: /downloads # загрузки, которые имеют связь с товарами
Кроме служебных файлов, важно оградить также служебные страницы. В этом случае директивы также могут иметь некоторые отличия исходя из CMS и структуры URL сайта:
• Корзина покупателя: Disallow: /cart/
• Процесс оформления заказа: /checkout/
• Метод сортировки: /*sort=*
• Способы сравнения представленного товара: /comparison/
• Кабинет пользователя: /my/
• Возможность регистрации: /signup/
• В ход в пользовательский кабинет: /login/
• Восстановление пароля: /remind/
• Перечень пожеланий: /whishlist/
• Страницы пользовательского кабинета: /users/
• Возможность поиска по тегам: /tag/
• Поисковая выдача: /*?*
• Фиды: */feed
• Лендинги, которые специально формировались под распродажи и различные акции: /landing-pages/
Ограждаются URL, включающие идентификаторы источников перехода:
• Из контекстной рекламы Google: /*gclid=*
• Из контекстной рекламы Яндекс: /*yclid=*
• Из партнерки: /*?ref=
• По линкам, имеющие метки from: /*from=
• По линкам, имеющие метки openstat: /*openstat=
Кроме того, можно оградить доступ роботам, которые создают большую нагрузку на серверную часть сайта:
• Роботы, анализирующие ссылки Ahrefs:
User-agent: AhrefsBot
Disallow: /
• Роботы, анализирующие ссылки Majestic:
User-agent: MJ12bot
Disallow: /
• Роботы поисковика Yahoo:
User-agent: Slurp
Disallow: /
В интернете существует большой перечень нежелательных роботов, от которых следует оградить собственный сайт, но прежде, чем это сделать, важно убедится, что это никак негативным образом не скажется на объеме трафика.
После того, как будет сформирован файл с директивами, его следует проверить на правильность с помощью Яндекс.Вебмастера и GoogleSearchConsole. При отсутствии ошибок, файл robots.txt помещается в корень веб-ресурса.
Robots.txt для поддоменов
В том случае, если сайт используется сразу несколько поддоменов, то все данные домена и его поддоменов, будут находиться в единой корневой папке. По этой причине, поисковой робот будет использовать лишь те директивы, которые указаны лишь в одном файле под названием robots.txt.
Для настройки разных директив в отношении домена и поддоменов, нужно создать отдельный файл robots-subdomains.txt с последующим его размещением в корневой папке сайта.
Недостатки robots.txt
Основным минусом robots.txt является то, что для поисковиков его директивы исполняются в необязательном порядке. Все настройки в robots.txt выступают лишь в роли указания, но не конкретной команды. Также нужно учесть, что если на огражденную страницу можно попасть через внешние линки, то поисковики попадут на страницу через них, после чего ее проиндексируют.
Рассмотрим подобную ситуацию. Сайт по продаже обуви имеет отдельную страницу, где можно сравнить товар. В robots.txt есть директива, закрывающая эту ссылку от роботов:

Но в случае введения адреса этой страницы в поисковой системе Google, можно наблюдать следующую картинку:
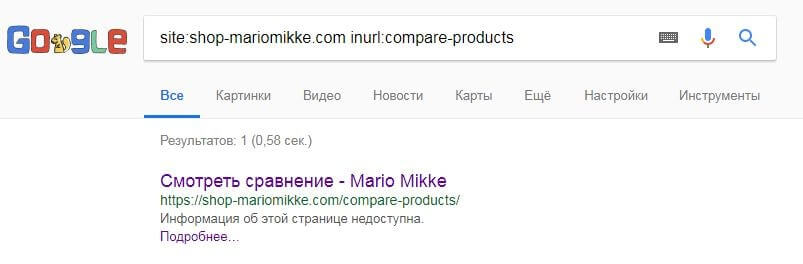
Эта ссылка была полностью индексирована и на нее можно перейти. Подобное происходит из-за того, что система индексирует все огражденные ссылки, прописанные в robots.txt.
Для удаления такой страницы из индексации, сперва нужно через robots.txt предоставить поисковику к ней доступ, после полной ее индексации ее нужно оградить с использованием мета-тегаrobots с прописанным значением “noindex,nofollow”. Подобный вариант намного надежней.
Чтоб полностью оградить определенные страницы от индексации поисковыми роботами, рекомендуется их дополнительно защищать паролем.
Кроме того, можно использовать мета-тегаrobots, что гарантирует полное закрытие страницы от индексации роботами поисковых систем. Также, за счет его использования, можно дать возможность поисковым роботам заходить на страницы без их индексации или же, наоборот, индексировать их без перехода. Для этого используются такие значения, как: noindex,follow и “ndex,nofollow.
Не только директивы robots.txt прямо влияют на корректность индексации конкретных страниц сайта. Существует большой массив различных нюансов, которые нужно учесть для того, чтоб в поисковую выдачу не попал "мусор" или же важна информации и персональные данные пользователей.
